There is more to say about testing dynamic reports.
In part 1, the focus was on describing how manual testing is done.
But sometimes, more than manual testing is possible, is it not?
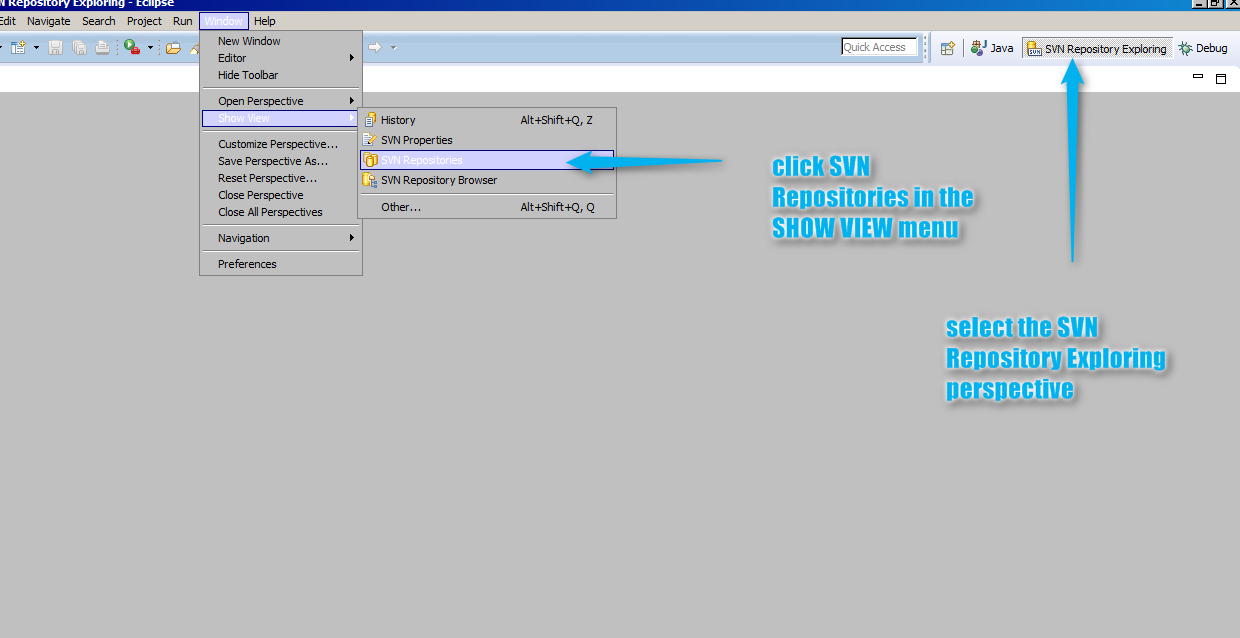
Let's have another look at the same report dashboard.
Mousing over a part of a sub-report will display a popup with various info:

As discussed in part 1, you will need a stored procedure or more (with parameters) to verify all information from the popup.
But is it possible to automate this testing?
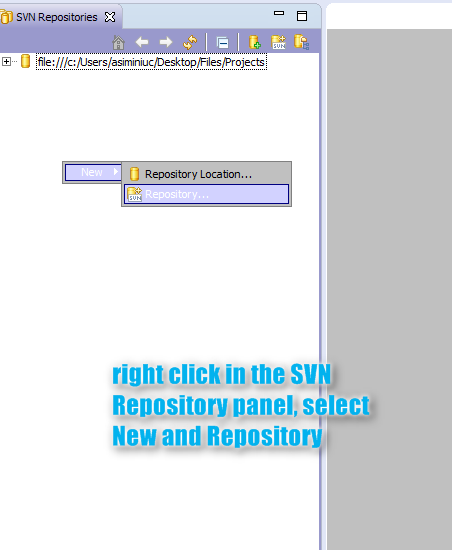
A closer look at the report shows that the report data can be exported in a cross tab format (CSV):

The export file is very simple (the highlighting is mine):

What about creating a Java app that
- reads the content of the CSV file and stores it in some sort of a list
- runs the stored procedures for all elements of the report dashboard and stores the results in another list
- compares the results of the 2 lists (one from CSV, the second from stored procedures)
Is there a better way for regression testing of dynamic reports?
In part 1, the focus was on describing how manual testing is done.
But sometimes, more than manual testing is possible, is it not?
Let's have another look at the same report dashboard.
Mousing over a part of a sub-report will display a popup with various info:
As discussed in part 1, you will need a stored procedure or more (with parameters) to verify all information from the popup.
But is it possible to automate this testing?
A closer look at the report shows that the report data can be exported in a cross tab format (CSV):
The export file is very simple (the highlighting is mine):
What about creating a Java app that
- reads the content of the CSV file and stores it in some sort of a list
- runs the stored procedures for all elements of the report dashboard and stores the results in another list
- compares the results of the 2 lists (one from CSV, the second from stored procedures)
Is there a better way for regression testing of dynamic reports?